|
In this post I'll discuss how to create a free classification task, also known as a free sort task, which we apply to non-native perception in Daidone, Kruger, and Lidster (2015). This task is useful for determining the perceptual similarity of non-native sounds and examining what acoustic, phonological, or indexical dimensions of the stimuli matter for listeners. It can be used to examine segmental or suprasegmental phenomena and can be used to predict their discriminability (check out our slides from New Sounds 2019). Here is an example of what our Finnish length free classification task looks like in PowerPoint. The numbers on the slide are sound files that participants click on and listen to and then group by which seem similar to them.  To choose the stimuli for a free classification task, I recommend including all related sounds if possible, such as all the vowels in that language. If not, when it comes time to do a multi-dimensional scaling analysis and correlations with properties of the stimuli, the results may be difficult to interpret because listeners don't need to use all of the relevant dimensions to group the stimuli. For example, if you only include front vowels in your task, it may appear in your analysis that F2, or vowel backness, is not a relevant dimension for grouping vowels, when actually it is an artifact of the stimuli you picked. Once you decide what sounds you want to examine, you will need to determine what phonetic contexts you want to use. I recommend two or three different contexts, since perception may differ between them, and you'll have more data points. In our German vowel experiment, we used both an alveolar context (/ʃtVt/) and velar context (/skVk/), and in our Finnish length experiment we used three contexts (pata, tiki, kupu). The stimuli for each context will be on a separate slide. Next, you'll need to figure out how many speakers you should record, which will determine how many stimuli you have per slide. I think that 30 stimuli per slide is the upper limit, since it becomes increasingly difficult to compare all the sound files to each other the more you have. For example, in our German experiment, since we looked at 14 different vowels, we only had 2 speakers, such that each slide contained 28 stimuli. For our Finnish length experiment, we looked at 8 possible length templates (CVCV, CVVCV, CVVCCV, etc.), and thus we chose to have 3 different speakers, for a total of 24 stimuli on each slide. Keep in mind that if you have few stimuli to group per slide, you'll have fewer data points for your analysis. When you have your list of stimuli for each slide, you'll have to decide which number each stimulus will have. These should be randomized so that participants can't use the numbers to group the stimuli. If you want to use our R script for analyzing results, you should create a file like the one pictured below to record which numbers and slides correspond to which stimuli. This should then be saved as a tab-separated text file. We have called this file a "Lookup Matrix" and our example one for the Finnish length experiment is available here. 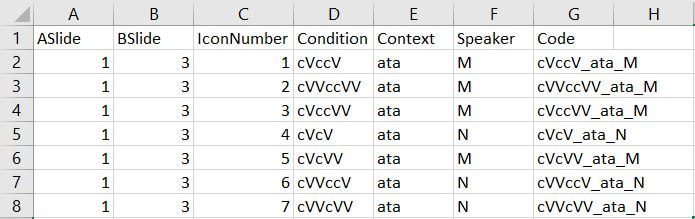 We have two versions of the task, Version A with the "ata" context first and Version B with the "upu" context first. Only the order of slides differs, rather than what is on the slides themselves. ASlide and BSlide refer to which slide contains which context within each version. In this case, the "ata" context is on slide 1 for Version A but on slide 3 for Version B. IconNumber refers to the random number that each stimulus is given. For Finnish length, Condition refers to the length template of each stimulus (e.g. stimulus 1 is [patta]). For your own task, this may be the target vowel or consonant for that stimulus. Code is the columns Condition, Context, and Speaker concatenated together. Once you have the sound files and their corresponding random numbers ready, you’ll need to insert all the sound files into PowerPoint and change their images to the appropriate number icon. Insert the sound file and change the image for each one by one to lessen the possibility of mixing up the numbers. A sample PowerPoint with grid can be downloaded here. Number images 1-28 are available here. The following instructions work with Office 365. To insert a sound file into PowerPoint: Go to “Insert” --> “Audio” --> “Audio on my PC”  After you’ve chosen a sound file, it will show up with a speaker icon. You will need to change this icon to the picture of a number by clicking on the icon, clicking on "Audio Format" in the top ribbon, and then clicking on “Change Picture” and choosing the appropriate image file. 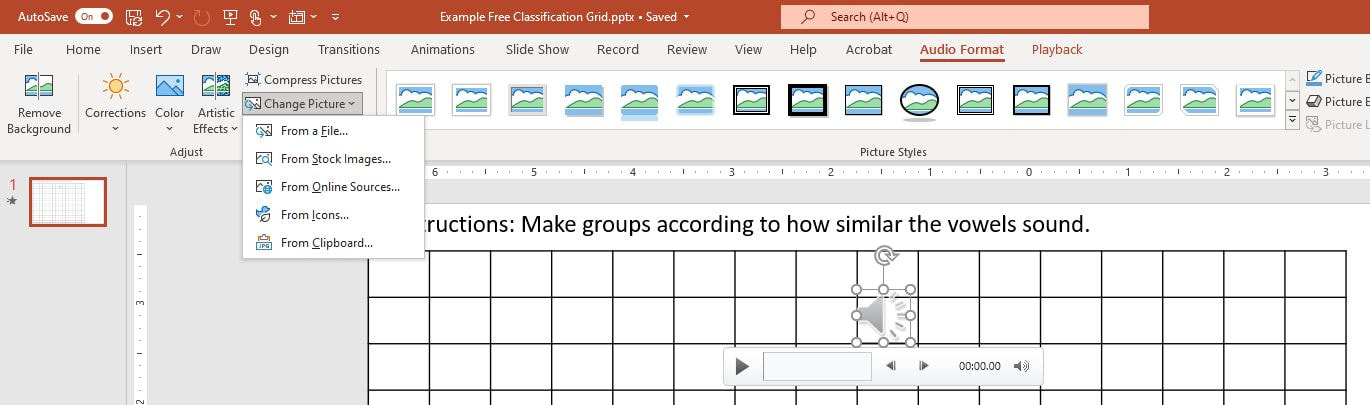 Now that you have a number icon for the sound file, you can add a border to it by clicking on "Picture Border". Make sure the color is black and the width is 0.75. 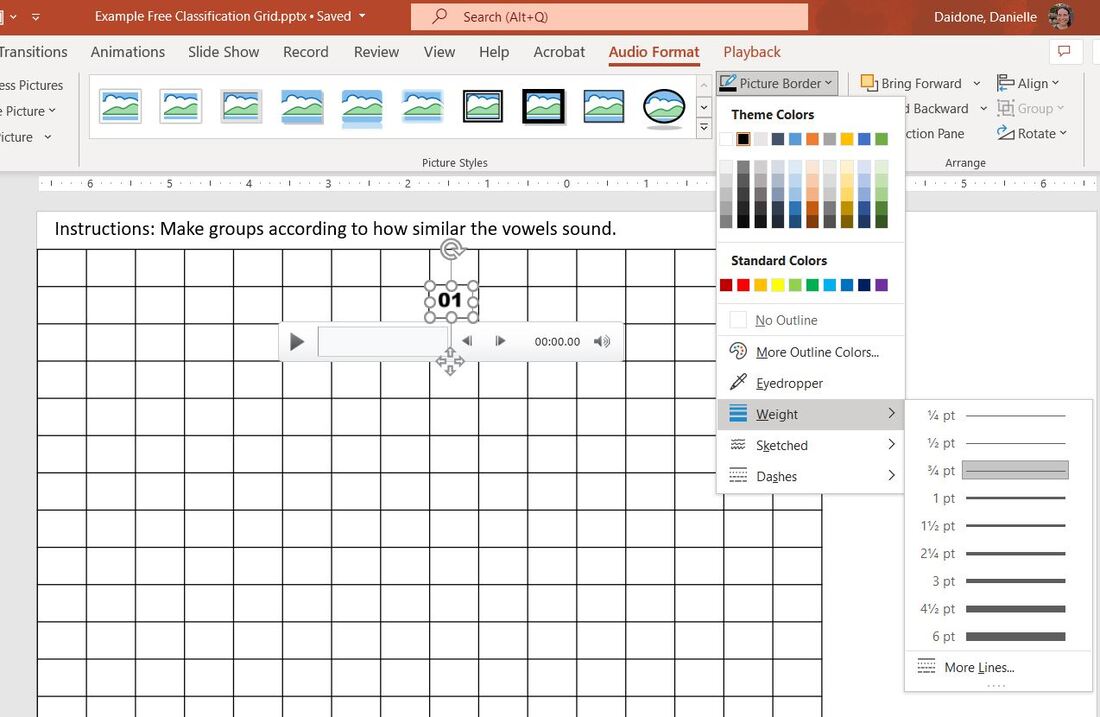 To adjust the size of the images, I recommend specifying the height and width to ensure uniformity across the images rather than manually adjusting the size of each by eyeballing it. Images that are 0.46” high x 0.61” wide fit nicely into the rectangles of the grid. You can specify the size of the image on the right size of the ribbon. Follow these steps for the sound files and numbers for all your slides and you're ready to go!  For a participant to complete a free classification task takes about 10-20 minutes, depending on how many stimuli they have to group and how obsessively they listen to everything. You can remind participants that there is no right answer and that they can make groups of any size as long as there are at least two sound files in a group. They can also arrange groups however they want as long as the divisions between groups are clear. Where they put the groups on the grid, or even if they use the grid, does not matter for the analysis. Once a participant finishes, we always check to make sure their groups are clearly delineated and that they don't have any single sound files without a group. The PowerPoint file is then saved with the participant name for later coding. Here are some examples of how participants have completed a free classification slide.  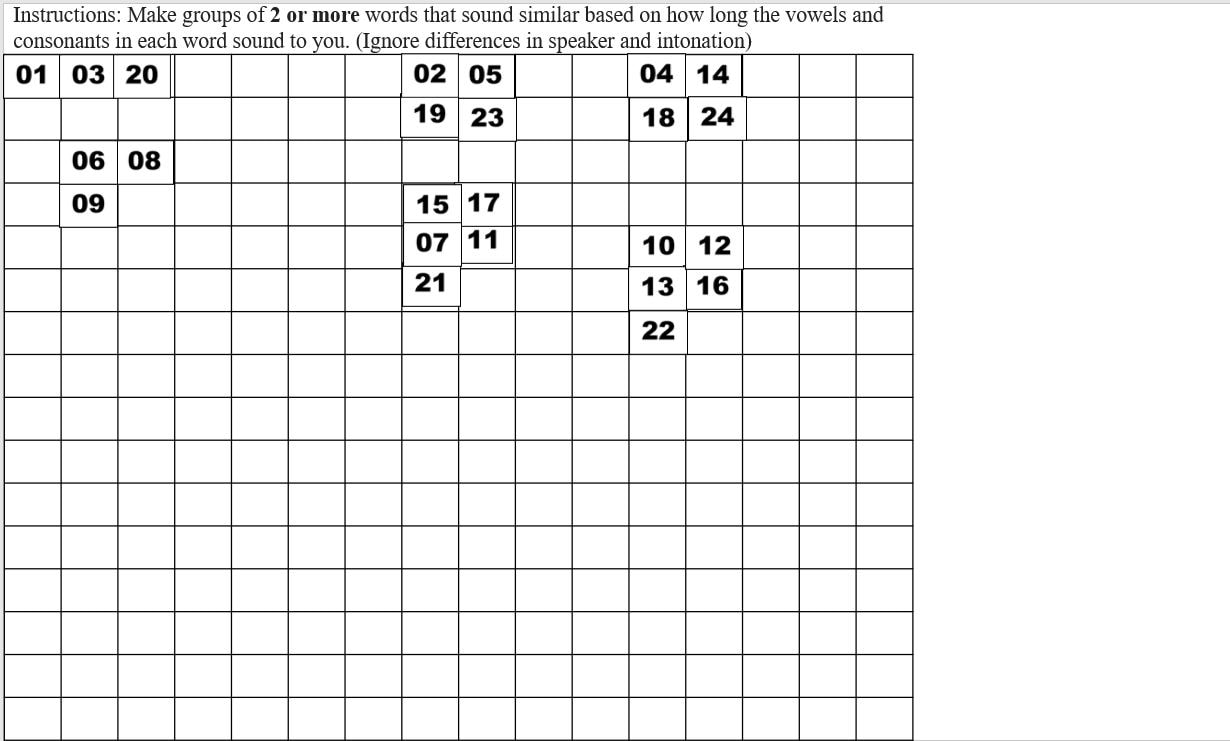  Additional tips:
0 Comments
Leave a Reply. |
AuthorI like sounds. Here I'll teach you how to play with them and force other people to listen to them. For science. Archives
August 2023
Categories |
 RSS Feed
RSS Feed